アイキューブドシステムズでCLOMOシステムの運用・監視をしているd-tasakiです。プラットフォーム運用部という部署に所属しています。「CLOMOシステムを絶対に止めない!」を部署のミッションとして、システムの安定的な提供を日々心掛けております。
2010年にサービスインしたCLOMOはアーキテクチャを少しずつ変えながら成長してきました。途中でAWSからAzureへとクラウド基盤を移すこともありましたが、いわゆる仮想マシンをベースとしたクラウドシステムとして構築し、運用していました。
2019年8月末にそれまでの仮想マシンをベースとしたシステムから、コンテナーをベースとしたAzure Kubernetes Service (AKS)に乗り換えました。そのbefore/afterの話を今回は書きます。
前回はCLOMOの開発環境をDocker化した話だったので、アンサーソングのようになってしまいましたが、全然別の話です(笑)
また、Kubernetesのメリットを書くだけではつまらないので、CLOMOシステム特有の話も踏まえます。
CLOMOについて
CLOMOは Mobile Device Management (MDM) システムです。簡単に言えば、スマートフォンなどの端末をリモート管理できるシステムです。
CLOMOには端末管理用のコンソールがあり、そのWebUIを操作するユーザーは企業の情報システム部門の担当者などです。
例えば、1万人の従業員に貸与するスマートフォンを初期セットアップしたり、日々運用管理したり、といったユースケースを思い浮かべていただければ、かなり大変な作業になることは想像に難くないと思います。そんな大変な作業を省いたり、1万台の端末のセキュリティリスクを低減したりするシステムがCLOMOです。
仮想マシンベースCLOMOシステム
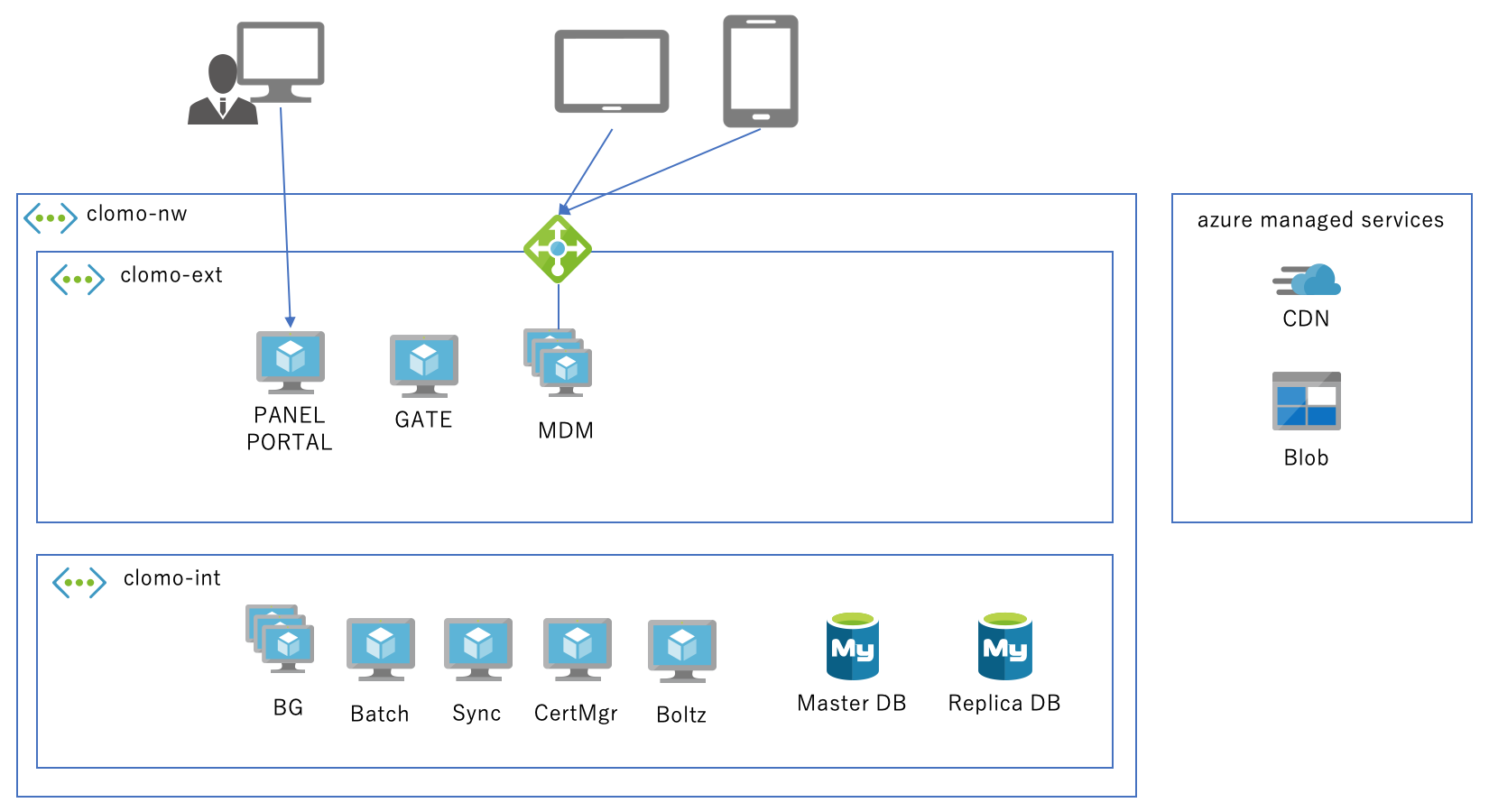
CLOMOは、以下のように複数のサーバーアプリケーションで構成されています。
- ユーザーが利用するWebサーバー (PANEL)
- 多数のデバイスが通信するAPIサーバー (MDM)
- 非同期処理を実行するバックグラウンドサーバー (BG)
- などなど
顧客ごとに上図の構成を作るのではなく、全顧客を1つのシステムで運用するマルチテナント型です。
Azureの仮想マシンを利用していた頃は、各サーバーアプリケーションに必要な台数の仮想マシンを割り当てるシンプルな構成でした。
PANELはMDMに比べればアクセスは少なく、1台の仮想マシンで賄えるくらいの規模でした。
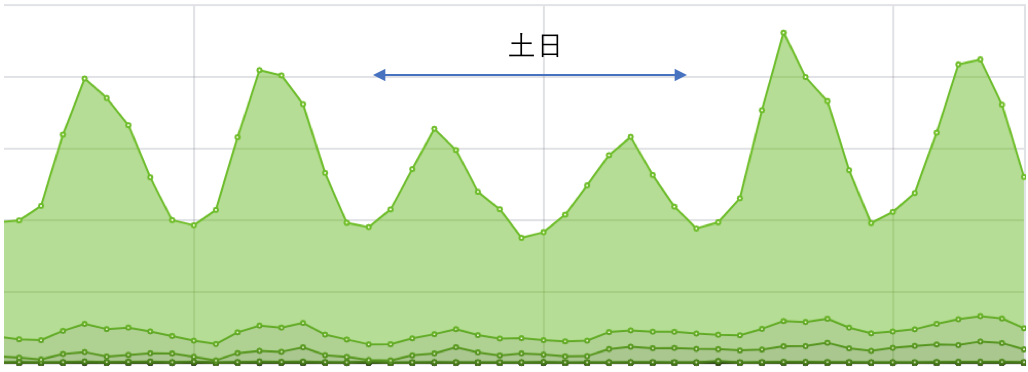
MDMは多数のデバイスが同時にアクセスするためAzureロードバランサーを前段に置いて、後ろは複数の仮想マシンで冗長化していました。 B2Bのプロダクトであるため、夜間や土日はアクセスが比較的少なくなる傾向にあり、時間帯や曜日に応じて冗長化している仮想マシンの一部を起動・停止させることでスケールさせていました。
仮想マシンベースCLOMOの課題事項
仮想マシンをベースとしたCLOMOシステムには以下のような課題事項がありました。
- 単一障害点が存在する
- スケールしにくい
- 非同期処理が滞留しがち
- リリース作業量が多い
単一障害点が存在する
CLOMOのロジックの一部にはPANELサーバーのローカルファイルシステムに依存しているところがありました。例えば、ユーザー情報のインポートなどの非同期処理で必要になるCSVファイルは、PANELサーバーのローカルファイルとして一旦保存しBGサーバーからそのファイルをscpで取得しにいくという、1台構成だからこそできる方法で実現されていました。
そのためPANELサーバーは、負荷分散・冗長化できる構成になっておらず、単一障害点となっていました。
これからサービスを設計するのであれば、このような構成にはしないと思います。しかしCLOMOがサービスインしたのは10年前で、当時はサーバー管理コストを優先したコンパクトな構成が理にかなっていたのでしょう。
その後、サービスの成長とともに、MDMなどはスケールできる構成へと変化していけたのですが、PANELのこの部分だけはなかなか手を付けられず、そのままシングル構成が続いてしまっていました。
スケールしにくい
前述の通り、MDMサーバーやBGサーバーなどは、それぞれ役割を決めて作成してありました。
例えば、MDMにアクセスが集中しているからといってBGサーバーに処理をさせるようなことはできません。役割ごとに仮想マシンを分けているため、どうしてもCPU・メモリを使い切れず余剰リソースが点在していました。
MDMサーバーを増やそうとしても仮想マシンを一からセットアップすると、ansibleで自動化してあったとはいえ軽く1時間はかかっていたと思います。
そのため、事前に予想したアクセス数上限に合わせてサーバーをセットアップしておき、休眠させておくくらいの手段しかありませんでした。休眠させてあったとしても起動するまでに時間がかかるため、スパイク的なアクセスの急増には追従できませんでした。
非同期処理が滞留しがち
非同期処理は1秒もかからず終わるものから、10時間以上かかるものまでいろいろな処理をしています。
非同期処理専用にCPU・メモリともに多めのサーバーを複数台確保して負荷分散・冗長化していました。 通常運用時には充分な構成ではありますが、一時的に非同期処理キューに処理が溜まることがありました。スケールしにくい課題と同じくBGサーバーをすぐに増やすということは難しかったです。
リリース作業量が多い
仮想マシン群へのアプリケーションリリース作業は、ansibleを利用して自動化していました。
しかしながら、リリース後にサービスが正常に疎通するかどうかまで自動チェックする仕組みを構築していなかったため、ansibleの実行を見守り、サーバー内のプロセスが正しく再起動かかっているかなどを手動で確認していました。
これにより、リリース作業には毎回1〜2時間くらいかかっていました。
コンテナーベースCLOMOシステム
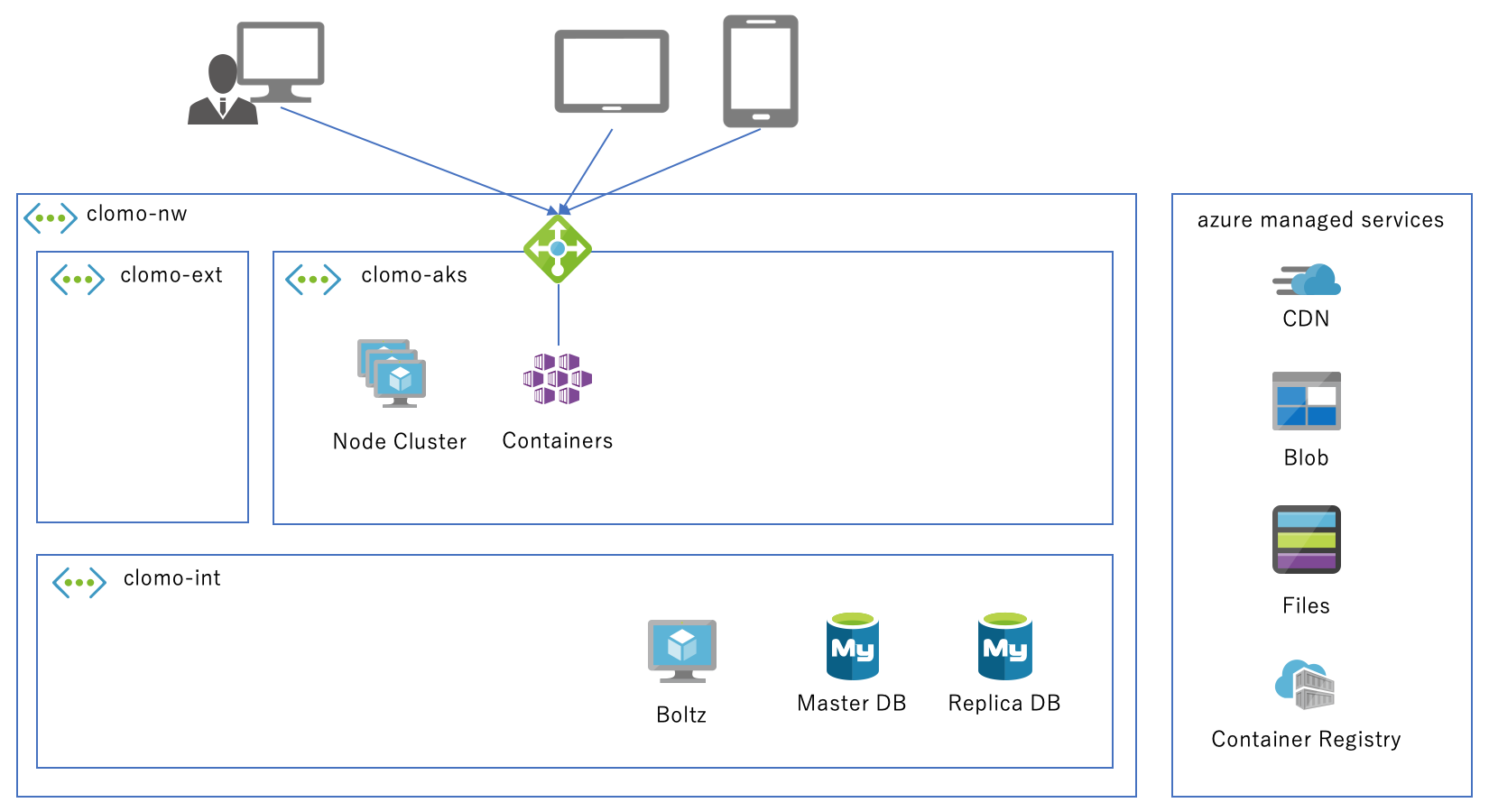
AKSを利用した構成に移行しました。上図のように構成がかなりスッキリしました。
図中には現れていませんが、Netflix社が公開しているOSSツールであるSpinnakerを用いてKubernetesのマニフェストを作成しデプロイしています。検証環境用AKSと本番環境用AKSを1つのUIで管理できるため非常に便利です。
Kubernetes初学者だった当時の私には、YAML地獄に陥ることなくGUIで設定できることはとても助かりました。
効果
AKSに移行した当初はなにかとバタバタしていましたが、1年近く運用していて下記のような効果を実感しています。
- 単一障害点を解消できた
- スケールしやすくなった
- 非同期処理が滞留しにくくなった
- リリース作業量が減った
単一障害点を解消できた
PANELサーバーのローカルファイルシステムに依存していた箇所は、PersistentVolumeClaimでReadWriteManyなストレージを要求してマウントしました。いわゆる共有フォルダーです。Azureの場合、Azure Files というSMB3.0を利用したネットワークディスクとしてマウントされるようです。
ローカルファイルとして保存せず共有フォルダーに保存するようにし、PANELやBGなど複数のpodから同じファイルを参照することでローカルファイルシステムに依存していた課題を解消させました。
本当はロジックを改修して Azure Blob を経由するにして一時ファイルをきちんと管理したかったところですが、とりあえずAKSに移行し単一障害点を解消するという目的は果たしました。
スケールしやすくなった
podのスケール
podは役割ごとに作られていますが、それを動かすノードは一部を除き役割を定めていません。そのため MDM pod はアクセス数に応じて、また BG pod は非同期処理の実行待ちキューの長さに応じて柔軟に増やすことができ、CPU・メモリに余裕のあるノードにKubernetesが適切に配置してくれるようになりました。つまり、仮想マシンに処理を凝集させて余剰リソースを極力使い切れるようになりました。
ノードのスケール
ノードを自動スケーリングする機能がAKSにあります。しかし、CPU使用率などの指標でスケールさせてもうまくCLOMOワークロードに合いませんでした。またAKS移行当時はプレビュー機能であったこともありCLOMOでは採用しませんでした。
AKS移行後の1,2ヶ月間くらいは毎晩 kubectl drain コマンドを使ってpodを退避させてノード仮想マシンを停止させ、朝には再起動させるということを手動で実施していました。そんな折、私が海外出張にいくこととなり朝晩の手動スケールができないのはまずいということで急いで自動スケール機能を作りました。
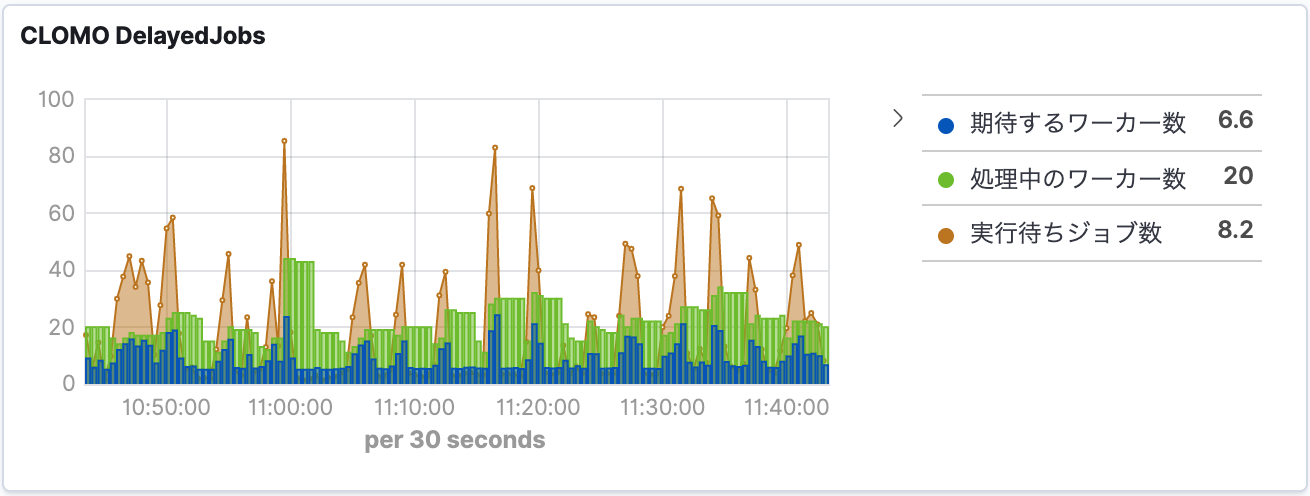
私は普段から Ruby on Rails に慣れ親しんでいるため、KubernetesとAzureの Ruby SDK を使って実装しました。スケーリングする際の指標には1ノードあたりのpod数を利用しています。これがCLOMOのワークロードとうまく合っており、今では下図のようにアクセス数や非同期処理数に応じてpodもノードもうまくスケールしています。
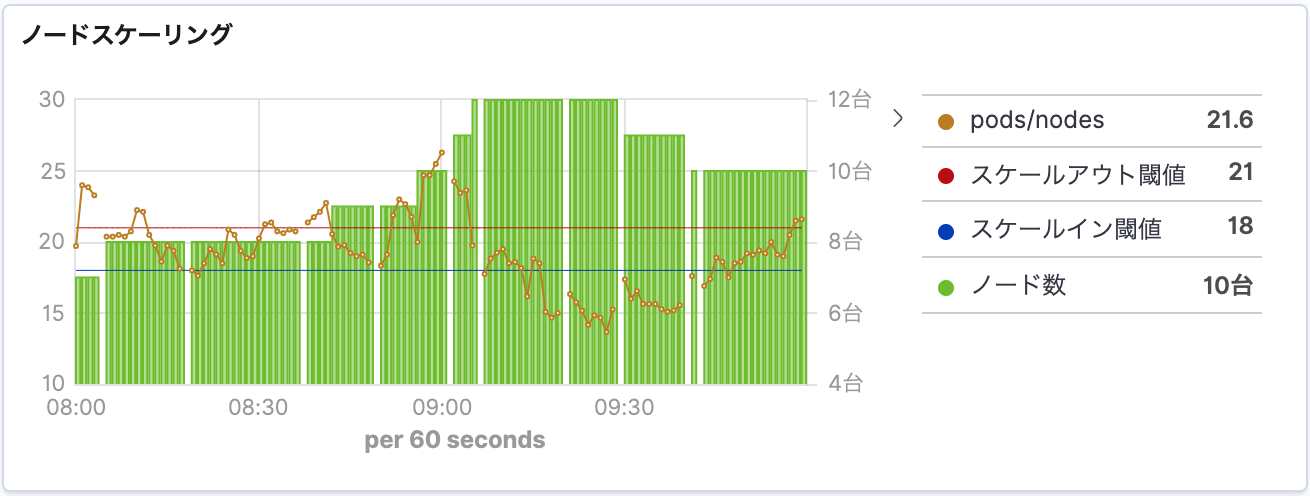
非同期処理が滞留しにくくなった
MDMはWebAPIであるため、アクセス数が増えればCPU負荷が高まります。そのためKubernetesの Horizontal Pod Autoscaler (HPA) 機能をうまく利用することができました。
一方、非同期処理はCPU負荷ではなく、キューに未実行処理が溜まっている数に従ってスケールさせた方が効率的です。HPAにはカスタムメトリクスに従ってスケールさせる機能がありますが、Kubernetes初学者だった当時の私には難易度が高かったです(悔しい)。
そこで、キューの実行待ちジョブ数をチェックし、BG pod 数を自動的に増減させる仕組みをRubyで自作しました。定期バッチで運用してみたところ、以下の図のように期待通りに動作しています。
リリース作業量が減った
ansibleでリリースしていたときは、再起動後の疎通確認が必要だったことは前述しましたが、その他にも、検証環境と本番環境とで実行環境やライブラリの微妙なバージョンの違いがないことを確認する作業もありました。とても時間がかかっていました。
Kubernetesでは検証フェーズで利用したdockerイメージをそのまま次のフェーズで利用するため、気を遣わないといけない箇所が減りました。
実行環境は同じdockerイメージになるため、検証環境・本番環境の違いはKubernetesのConfigMapやSecretを使って注入する設定値だけに気をつければよくなり、関心事が一箇所に集約されたことはとても助かります。
また、Spinnakerを利用しているためGUIでポチポチっとやるだけでデプロイが始まり、Kubernetesの機能でサービスが停止しないようにうまい具合にローリングアップデートしてくれます。
う〜ん、楽!
ansibleを使っていたころは1〜2時間くらいかかっていたリリース作業が、10分程度で終わるようになりました。
落とし穴
AKS移行は全て順調にいったわけではなく、いろいろな落とし穴にハマりました。以下で紹介します。
- CLOMOのアーキテクチャによる落とし穴
- Kubernetesによる落とし穴
- AKSによる落とし穴
CLOMOのアーキテクチャによる落とし穴
KubernetesではノードのOSバージョンアップ(Kured)のためだったりオートスケーリングのためだったりで停止・起動されることがあります。そのためノードに配置されているpodはいつでも削除される可能性があります。削除されてもKubernetesのオートヒーリング機能ですぐに望む数のpodが立ち上がってくるので問題はありません。しかしこれは、podで動いているプロセスが状態を持たずgracefulな停止(実行中の処理が終わってからプロセス終了)に対応できている場合に限ります。
AKS移行前からPANELやMDMにはgracefulに停止する機能を実現してありました。BGも10時間以上継続するような非同期処理もありますが、それでもgracefulに停止する機能がありました。AKS移行後でもPANELやMDMはgracefulな停止に対応させています。BGの場合は terminationGracePeriodSeconds をとりあえず20時間に設定することで処理が完了するのを待つようにしています。
一方で、日次バッチ処理には20時間以上も動作しているものがあります。AKS移行前はバッチサーバーとして専用の仮想マシンを確保して実行していました。AKSに移行してからはKubernetesのJobとして実行するようにしたのですが、これがgracefulな停止に対応していませんでした。処理の途中で不意に削除され、再実行されるもまた最初からやり直しという状態になっていました。
この対策としては、ノードに clomo/BatchDeployable というラベルを付与し、日次バッチはラベルセレクターを使って合致するノードでしか実行されないようにしました。また、ノードのオートスケール時には clomo/BatchDeployable ラベルが付与されているノードは停止対象外とするようにしました。これで日次バッチ処理は最後まで処理することができるようになりました。
Kubernetesによる落とし穴
Kubernetesのスケジューラーはpodを配置するときにCPU・メモリに余裕があるノードを選択するように動作します。既に配置済みのpodを別のノードに移動するということは基本的にやりません。そのため、新しいノードが起動した場合などにpodが偏って配置される状態になることがあります。(図で理解するDescheduler ← こちらの資料がとてもわかりやすいです)
CLOMOでは特定のノードだけメモリ消費が多いという形で検知されることが多かったです。
このような偏りを検知し均一にしてくれるdeschedulerというものをKubernetesに組み込むことができますが、前述のようにgracefulな停止に対応していないpodがあるためこれを利用することができませんでした。
そこで、はい。また自作しました。オリジナルのdeschedulerを参考にしながら、特定のラベルがついているpodたちだけを有効なノードたちの間で均一になるように削除する機能をRubyで。オレオレdeschedulerを動かし始めてからはメモリ消費が多いという警告が発生する回数が随分減りました。
AKSによる落とし穴
1ノードあたり30podしか配置できなかった
AKSクラスターで利用される Azure CNI というネットワークの制約のためか、1ノードあたりに30podしか配置できないです (参考: ノードごとの最大ポッド数)。 Azure CLI を使ってAKSクラスターを作成するときはオプション指定でこの値を変更できるようですが、Azure PortalでAKSクラスターを作成しようとすると最大pod数は指定するUIがありませんでした。
この制約に気づいたのはAKS移行して運用し始めてからでした。一度作成したAKSクラスターの最大pod数を変更することはできず、変更したければ新しくAKSクラスターをCLI経由で作り直さなければならないとのこと。CPU・メモリをあまり消費していないpodたちも多くいるため、この制約がなければもっと凝集度を上げることができるのにと悔やんでいます。
Azure Filesが結構遅い
PANELの単一障害点を克服するためにPersistentVolumeを使って Azure Files を共有フォルダのように使っているのですが、ここへのI/Oが結構遅い。
以前の構成なら1分もかからなかった処理が、Azure Files を経由することで10分以上かかってしまうようになったものもあります。
Azure Files はpod間のファイルのやり取りのためだけに利用して、作業フォルダとしては使わないようにCLOMOのロジックを少しずつ修正しているところです。
まとめ
本番環境をKubernetesに移行した話でした。いろいろな落とし穴にハマりましたが、もともとステートレスでgracefulなアプリケーションであればもっとすんなりとKubernetesに馴染んでいたんだと思います。それでもなんとかAKS移行を達成し、安定した運用に加えて柔軟な運用ができるようになり多くのメリットを享受している日々です。
graceful, gracefulって何度も書いてきましたが、Kubernetes運用者からサーバーアプリケーション開発者へは、いつでもgracefulに停止、再開できるように作って欲しいと声を大にして言いたいです。
サービス設計の相談を受けたときに、いつも言っています。
ほんとうによろしくお願いします。