アイキューブドシステムズのd-tasakiです。本稿執筆時点では製品開発運用本部プラットフォーム運用部に所属しCLOMOシステムの日々の運用・監視をしていますが、以前は製品開発部に所属しておりCLOMOのWebアプリケーションの開発を経験していました。
Ruby on Railsで作られているCLOMOの開発と運用の両面を経験した知見をもとに、今回は特に非同期処理の部分について割と深めな話を書きたいと思います。同じようなRailsアプリケーションを開発している人や、そのアプリケーションをシステム運用している人たちの参考になれば幸いです。
CLOMOについて
CLOMOはMobile Device Management (MDM)システムです。簡単に言えば、スマートフォンなどのデバイスをリモート管理できるシステムです。CLOMOにはデバイス管理用のコンソールがあり、そのWebUIを操作するユーザーは企業の情報システム部門の担当者などです。
例えば、1万人の従業員に貸与するスマートフォンを初期セットアップしたり、日々運用管理したり、といったユースケースを思い浮かべていただければ、かなり大変な作業になることは想像に難くないと思います。そんな大変な作業を省いたり、1万台のデバイスのセキュリティリスクを低減したりするシステムがCLOMOです。
同期処理と非同期処理について
Webアプリケーションでは、WebブラウザやスマホアプリなどのクライアントからHTTPリクエストを受け付けレスポンスを返します。この一往復のリクエスト&レスポンスを同期処理と本稿では呼称します。
デバイス情報の取得などのリクエストには同期処理で充分対応できます。しかし、例えば数千台のデバイスにアプリインストールをしたい場合や、管理しているデバイス情報をCSVエクスポートしたい場合など数分〜数時間かかるような処理もあります。これらを同期処理で実施するとHTTPリクエストがタイムアウトして失敗してしまいます。そこで、このような処理を非同期ジョブとしてキューに追加しておいてHTTPレスポンスは即座に返すということをします。これを本稿では非同期処理と呼称します。
業務系システムでは夜間はアクセスを停止し、時間がかかる処理は夜間バッチでまとめて実施しているという話を聞いたことがあります。しかしながらCLOMOは24時間365日、常に稼働することを目指していますので停止せずに非同期処理を実施する必要があります。
DelayedJobで非同期処理
先に記述したようにCLOMOはRuby on Railsを使って実装しています。gitリポジトリのログを見ると最初のコミットは2010年7月でした。Rails3がリリースされる直前くらいの時期です。そのためCLOMOはRails2でプロトタイプが作成され長い間Rails2を使っていました。
Railsで非同期処理といえば、Rails4.2から導入されたActiveJobを使い、バックエンドとしてSidekiqやResuce、DelayedJobを選択できます。しかしRails2当時にはActiveJobのような抽象化した仕組みはなく、いずれかの非同期バックエンドを直接利用する必要がありました。筆者はCLOMO開発当初はまだ入社していなかったので選定理由は把握していませんが、CLOMOでは当初からDelayedJobを利用しています。
DelayedJobの使い方
さて前置きが長くなりましたが、ここから少しずつ深くコードの中やCLOMOでの実運用の話に入っていこうと思います。
Device.export(options) ↓ Device.delay.export(options)
DelayedJobでは、ほとんどのメソッド呼び出しを上記のようにdelayを間に入れるだけで非同期ジョブとしてキューに積んで、WebアプリケーションプロセスではなくバックグラウンドのDelayedJobワーカープロセスに処理させることができます。この手軽さはかなり衝撃的でした。
DelayedJobのバックエンド
SidekiqやRescueはバックエンドとしてRedisを別途用意する必要があります。一方でDelayedJobはRailsが使っているMySQLやPostgreSQLなどのデータベースにテーブルを一つ追加するだけで利用できます。
システム運用者目線で言えば、Redisを管理しなくてよいというのは非常に助かります。システムアーキテクチャにコンポーネントが一つ増えるだけで、死活監視、負荷状況確認、バックアップ&リストアなど運用の手間はいろいろ増えてしまいますので。
また、Railsで扱っている他のテーブルを参照するのと同じ感覚でSQLを発行すれば、実行中ジョブや実行待ちジョブの数などキューの状態を簡単に確認することができることも運用していく中で楽です。
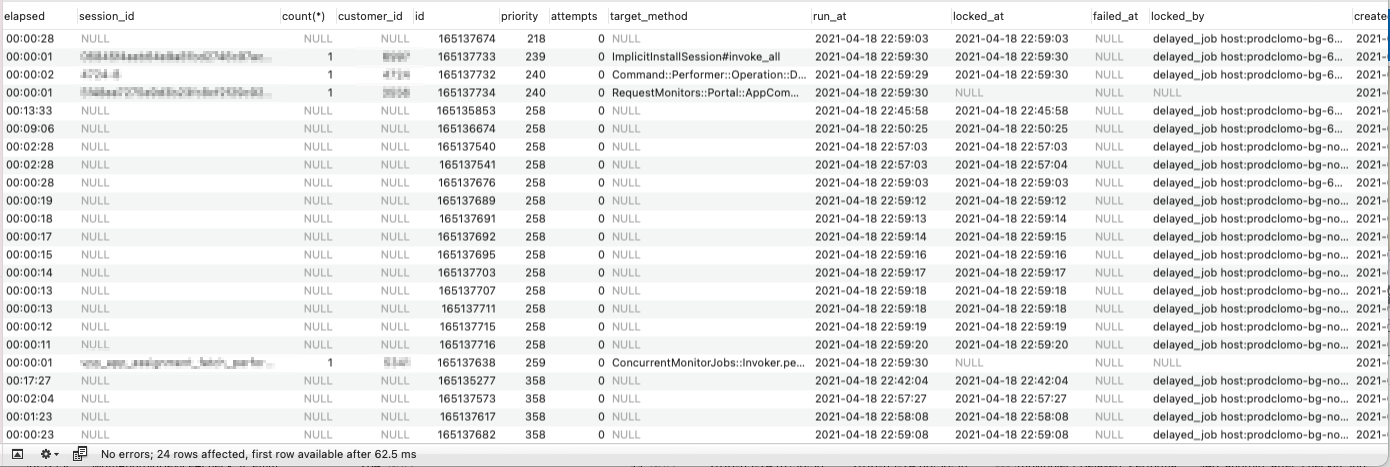
非同期ジョブごとの優先度設定
DelayedJobでは非同期ジョブごとに優先度を設定できます。なぜならSQLデータベースをバックエンドで利用しているため。次に実行すべきジョブがどのレコードか調べるSQLにorder by指定してやるだけで優先度順に処理することができます。
DelayedJobのコードでいうと↓あたり。
だいたい↓のようなSQLが発行されることになります。priorityカラムの値が小さいほど優先して処理されることとなります。
select * from delayed_jobs where ( ( run_at <= 現在時刻 and ( locked_at is null or locked_at < ロック解除時刻 ) ) or locked_by = "ホスト名+プロセス番号" ) and failed_at is null order by priority asc, run_at asc limit 5
以前のCLOMOでは優先度設定機能を特に使わずすべてpriority=0で非同期ジョブ登録していました。そのため例えば「従業員がスマホを紛失した!どこにあるかわからないけれど情報流出しないようにデータをいますぐ全部消したい!」というケースでCLOMOのリモートワイプ機能を実行するも、他の非同期ジョブが溜まっているとなかなか処理されないという状況が発生していました。
そこで非同期ジョブの優先度について再設計しました。CLOMOにおけるユースケースを分析すると非同期ジョブを登録するアクターは、管理者、エンドユーザー、システムの3者がいることがわかりました。
- 管理者: お客様の情報システム部門などに所属する人。CLOMOのWebUIを直接操作する人
- エンドユーザー: お客様の会社の従業員など。CLOMOに管理されているデバイスを利用する人たち。
- システム: CLOMO内部処理をするヒト
これらのアクターを考慮して下表のように優先度を定義しました。
| 優先度高 | 優先度中 | 優先度低 | |
|---|---|---|---|
| 管理者操作 | 120 | 220 | 320 |
| エンドユーザー起因 | 140 | 240 | 340 |
| システム都合 | 160 | 260 | 360 |
先述の事例のようにすぐにリモートワイプしたいということがあるため、基本的に管理者の意図を優先します (管理者操作 優先度中: 220)。
数千人、数万人のエンドユーザーたちがそれぞれ持つデバイスが一度にサーバーにアクセスしにきてそれぞれ非同期ジョブを登録していくことがあります。このような大量登録される可能性がある非同期ジョブは管理者よりやや優先度を落として登録します (エンドユーザー起因 優先度中: 240)。
スマートフォンを従業員に配布する前に情報システム部門で制限設定や業務用アプリケーションのインストールなどをまとめて実施することをキッティング作業といいます。1万台のスマートフォンをキッティングしてCLOMOの管理下にいれる際に非同期ジョブが滞留して1分、2分とキッティング作業者を待たせてしまうとキッティングスケジュールが大幅に遅延してしまう原因となることがあります。そのためキッティング時に登録される非同期ジョブは優先度を高くするように調整しています (エンドユーザー起因 優先度高: 140)。
CLOMOシステムでなにかしらのエラーを検知した場合にプラットフォーム部門に通知をしていますが、この処理は障害に気づくために重要であるため優先度を高く設定しています (システム都合 優先度高: 160)。
一方で、全デバイスに日次で処理しているものは24時間以内に終わりさえすればよいのでのんびりとジョブワーカーが暇なときに処理してもらうよう、優先度を下げています (システム都合 優先度低: 360)。
上述のものはあくまで一例ですが、原則としてこのような優先度を設定し、あとはジョブの種類によって±1,2程度優先度調整は許容するようにしました。このように優先度の整理をしたことでユーザーを待たせることが格段に減りました。
DelayedJobの魔改造
優先度を整理しただけでは解決できない課題がCLOMOにはありました。それは管理者が操作した順番通りに処理が行われないということです。
例えば、管理者がデバイスに以下の処理を実施したとします。
- 手順1: デバイス100台にアプリケーションAをインストール
- 手順2: デバイスBにはアプリケーションAはいらなかったのでアンインストール
DelayedJobは基本的に非同期キューに入っている実行待ちジョブを並列処理します。上記の手順1を処理している最中でも手順2の処理が並列処理されてしまいます。すると、デバイスBには先にアンインストール処理が実施され、その後にインストールが処理され、結果としてデバイスBにアプリケーションAがインストールされた状態になってしまうことがありました。これでは管理者の意図を反映しているとは言えません。
あえて直列化
この課題に対して我々は非同期処理でありながら並列ではなく直列に実行される仕組みを導入しました。
Rubyの特徴としてGemライブラリや組み込みのクラスを再オープンして改造することができます。安易な改造は副作用を起こすことがあるのであまり推奨されませんが、CLOMOの要件のためには改造せざるをえませんでした。
素のDelayedJobで非同期ジョブキューの中から次に実行すべきジョブを探すSQL文は下記です (再掲)。
select * from delayed_jobs where ( ( run_at <= 現在時刻 and ( locked_at is null or locked_at < ロック解除時刻 ) ) or locked_by = "ホスト名+プロセス番号" ) and failed_at is null order by priority asc, run_at asc limit 5
これをそーしてあーして、こうじゃ!
select delayed_jobs.* from ( ( /* セッション付きジョブ(セッションごとにひとつずつ) */ select cast(substring_index(group_concat(delayed_jobs.id order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as signed integer) as id, cast(substring_index(group_concat(delayed_jobs.priority order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as signed integer) as priority, cast(substring_index(group_concat(delayed_jobs.attempts order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as signed integer) as attempts, cast(substring_index(group_concat(delayed_jobs.run_at order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as datetime ) as run_at, cast(substring_index(group_concat(delayed_jobs.locked_at order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as datetime ) as locked_at, cast(substring_index(group_concat(delayed_jobs.failed_at order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as datetime ) as failed_at, substring_index(group_concat(delayed_jobs.locked_by order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as locked_by, cast(substring_index(group_concat(delayed_jobs.created_at order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as datetime ) as created_at, substring_index(group_concat(delayed_jobs.queue order by priority asc, run_at asc, delayed_jobs.id asc), ',', 1) as queue from delayed_jobs inner join delayed_job_processes on ( delayed_jobs.id = delayed_job_processes.delayed_job_id and delayed_jobs.created_at >= delayed_job_processes.created_at and delayed_jobs.created_at <= delayed_job_processes.updated_at ) where failed_at is null and delayed_job_processes.session_id is not null group by delayed_job_processes.session_id ) union ( /* セッションなしジョブ */ select delayed_jobs.id as id, delayed_jobs.priority as priority, delayed_jobs.attempts as attempts, delayed_jobs.run_at as run_at, delayed_jobs.locked_at as locked_at, delayed_jobs.failed_at as failed_at, delayed_jobs.locked_by as locked_by, delayed_jobs.created_at as created_at, delayed_jobs.queue as queue from delayed_jobs left join delayed_job_processes on ( delayed_jobs.id = delayed_job_processes.delayed_job_id and delayed_jobs.created_at >= delayed_job_processes.created_at and delayed_jobs.created_at <= delayed_job_processes.updated_at ) where failed_at is null and delayed_job_processes.session_id is null and ( run_at <= 現在時刻 and (locked_at is null or locked_at < ロック解除時刻) or locked_by = "ホスト名+プロセス番号" ) order by priority asc, run_at asc limit 30 ) ) as delayed_jobs where run_at <= 現在時刻 and (locked_at is null or locked_at < ロック解除時刻) or locked_by = "ホスト名+プロセス番号" order by priority asc, run_at asc limit 30
なんということでしょう。元は数行の単純なクエリだったのに、匠の技によりSQL職人の温かみを感じる壮大なクエリに生まれ変わったではありませんか。
変更したのは元のソースコードでいうと↓のDelayed::Backend::ActiveRecord::Job.ready_to_runメソッドだけです。魔改造といっても単一のメソッドに留めていますので影響は極々小さいものになります。
先の壮大なクエリの中にdelayed_job_processesというテーブルが出てきます。これは本課題とは別件で以前より導入していたもので、DelayedJobの進捗状況や処理結果を保持するテーブルです。このテーブルにセッションという概念を追加しました。
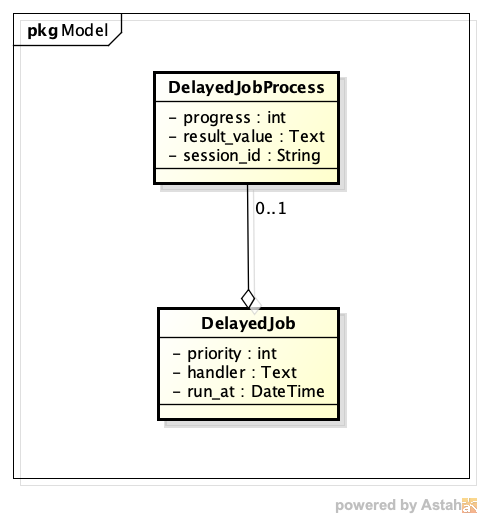
セッションは管理者ごとにユニークなIDです。セッションIDでgroup byし適切にorder byすることで同一管理者が登録した非同期ジョブは最大でも1つしか候補にならない(ジョブ処理中は候補に出てこない)ことになります。これを我々CLOMO開発者は非同期ジョブの直列化と呼んでいます。
セッション付きの直列化したジョブレコードと、セッションなしの通常のジョブレコードをunionで統合し、その中から次に実行すべきジョブを選定しています。
なお、DelayedJobには名前付きキューという機能があります。これを使った方が直列化に近しい機能を実現できますが、当時CLOMOが使っていたDelayedJobはver. 2系であり、名前付きキューがまだ実装されておらず、我々にはその選択肢はありませんでした。
でも負荷がお高いんでしょう?
壮大なSQLを実行していますので、その頻度が高くなればデータベースサーバーのCPUに負荷がかかります。
CLOMOではDelayedJobのワーカープロセスをKubernetesの1 podとして稼働させており、非同期ジョブキューの中の未実行ジョブ数に応じてpodの数を変動させて運用しています。本原稿執筆時点ではワーカーpodは5個〜60個まで変動させています (オートスケールの仕組みについてはまた別の機会にでも)。
CLOMOのとある機能を使うと瞬間的に1万件以上のセッションなしジョブが登録されることがあり、それらを最大60個のプロセスがガンガンに壮大なSQLを実行して我先にとジョブを掴みにくるわけですが、その規模のときは下記のグラフのようにデータベースのCPU負荷が急騰します。
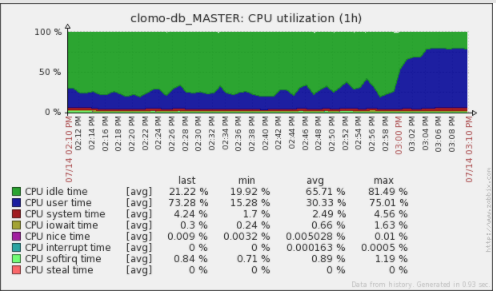
通常運用時の実行待ちジョブ数はだいたい数十〜数百件であり、データベースサーバーのCPU負荷はまだまだ余裕がありますので一応大丈夫です。
ちなみに、1万件以上の未実行ジョブが登録されたときにDelayedJobワーカーを最大60個から90個、120個と増やしてみましたが、時間あたりのジョブ処理数は増えませんでした。DelayedJobの設定値としてDelayed::Worker.read_ahead = 30を設定しています。各ワーカーが未実行ジョブを30件先読み(先の壮大なSQLのlimit 30の部分に該当)していることになるわけですが、ワーカー数が増えすぎると先読みした30件も全部他のワーカーに奪われてしまい、空振りに終わっているからではないかと推測しています。最大ワーカー数と先読み件数の調整は今後も続けていきたいと考えています。
ConcurrentJobの導入
とはいえ、ジョブ件数がデータベースサーバーのCPU負荷に直結していることは拭えない事実です。特に直列化したジョブが溜まると顕著に影響がでます。そして数万台規模のデバイスに対する非同期処理を実施したい要件もあり、何も考えずにジョブ登録してしまうとデータベースサーバーが悲鳴をあげ、システム全体が不安定となってしまいます。
新方式導入
そこで我々は考えました。DelayedJobキューとは別にメタ的なキューに数万件のジョブ情報を溜めておき、少しずつDelayedJobキューに投入するようにすればよいのではないかと。この仕組みをConcurrentJobと名付けました。
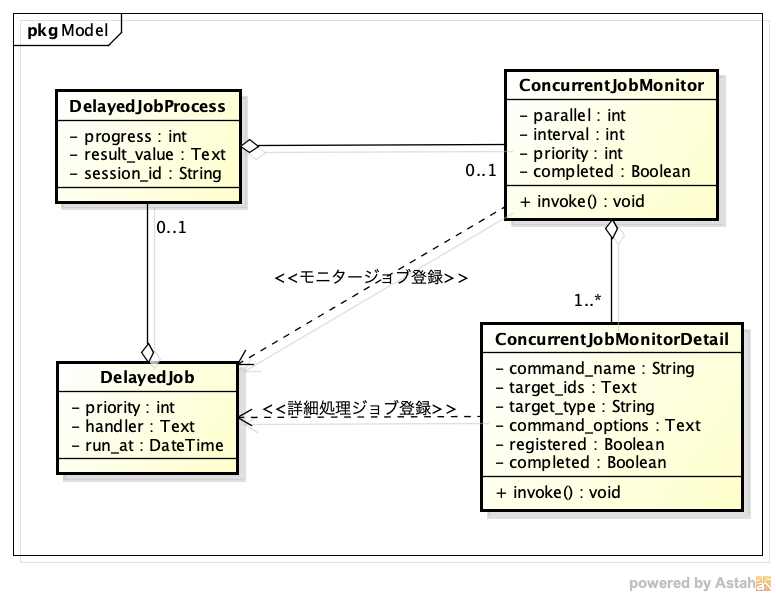
ConcurrentJobはRailsのModelで実現しました。ConcurrentJobMonitor (モニター) has many ConcurrentJobMonitorDetail (詳細処理) という関係です。モニターは詳細処理の状況を監視して、parallel (並列実行可能上限数) まで詳細処理のinvokeメソッドをdelay付きで呼び出しジョブ登録します。その後、interval秒後に再度モニター自身のinvokeを呼び出すようにdelay付きで呼び出してジョブ登録します。
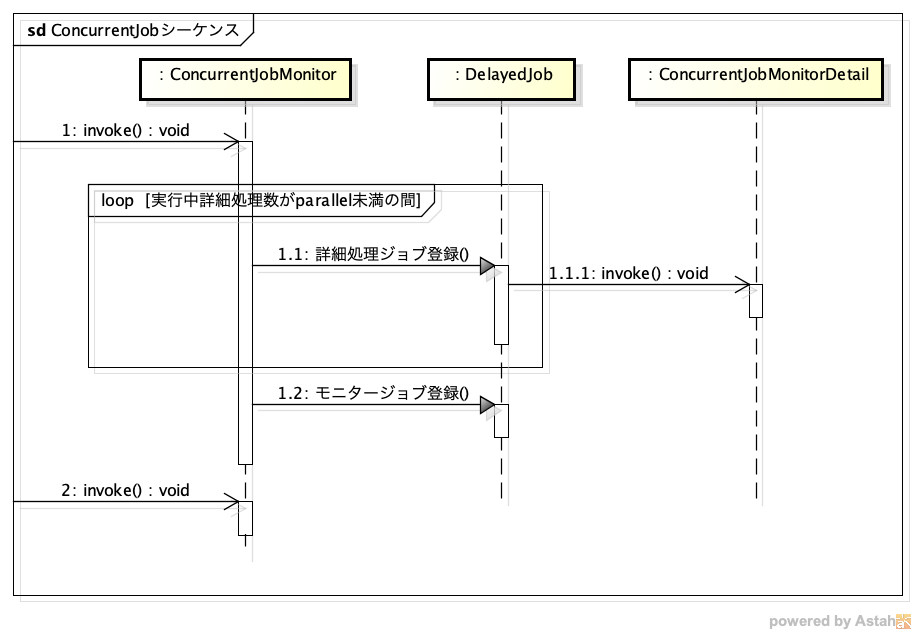
詳細処理は任意のクラスのメソッドを呼び出したり、複数のRailsモデルインスタンスを登録して任意のメソッドを呼び出ししたりすることができます。任意のクラス・インスタンスのメソッドを呼び出すという仕組み部分も興味深い点ですが本稿では割愛します。また別の機会にでも。
なにが嬉しいの?
言葉で説明しても図で説明してもよくわからない複雑なジョブ登録関係となってしまいましたが、それでも余りあるメリットがあります。それは、ConcurrentJobMonitorのparallelやinterval, priorityの値をデータベース上のレコードをいじるだけで実行中でも変更できるということです!
これまでは開発者がコーディングした通りにしか実行できませんでしたが、この仕組みなら運用中に並列度や優先度を変更することができるのです。特定のお客様が急ぎで処理を進めたいというときに優先度を高めたり、システム全体の負荷が高くなっていたら並列度を下げたりといった柔軟な運用ができるわけです!! また、ConcurrentJobMonitorDetailの状況をデータベースで閲覧すれば完了時刻を推測することもできます。システム運用者としてこれらのメリットは非常に嬉しいものです。
ConcurrentJobの仕組みのおかげで数万台に対する処理も小分けにしてジョブ登録でき、優先度設定もでき、モニター単位で直列化しながらも詳細処理は並列処理するということもできるようになりました。これまでのCLOMOの非同期処理の集大成といえるでしょう。
まとめ
CLOMOの非同期処理について苦労しながらも成長してきた様子の一端をお見せいたしました。ここまでお読みいただきましてありがとうございました。
Railsの非同期処理といえば、最近はSidekiq + Redisという構成が流行りだとは思いますが、DelayedJob + MySQLという組み合わせもなかなか味わい深いものです。Webシステムの開発と運用の両方を経験しているモノだからこその視点かもしれません。お読み頂いた方が抱えている要件に合わせてDelayedJobも検討してみていただければ幸いです。
さいごに。
We are hiring! CLOMOのさらなる成長を一緒に体験しましょう!